I have written about missing the semi colon on the end of an IDE-completed line of code, and the various options for addressing it.
When I eventually disabled code completion, I found that the impact it had on typing speed was negligible. By turning it off I also gained something surprising: my ability to understand and recall the code I had just written improved. By typing in the closing } and ) that I had gotten so used to always being there, somehow mentally, my mind also captured the contained information better. It got closure for each function that it, well, closed.
Throw away your code completion
Take the noose off your ambition
Re-invent your intuition now
Typing an open { is telling my mind: “you have opened a function definition”, then I go about my business typing it out, maybe opening new { or ( for whatever reason, but always closing ) them } in order. In my mind, I still have the notion of something unfinished, until I type the final closing }. When the IDE adds it automatically, it removes pieces of the mental image I form of the code I just typed.
Try it out, it might surprise you just the same.
Renegades with fancy gauges
Slay the plague for it's contagious
Pull the plug and take the stages
Throw away your code completion now
As a programmer writing Rust in VS Code on Mac, I type
let s = String::from(
^
and the editor gives me a closing ) and places the cursor between the parens:
let s = String::from()
^
I then type a double quote:
let s = String::from(")
^
and the editor automatically adds a second " and places my cursor between the two quotes:
let s = String::from("")
^
I type in the text inside the double quotes, say “Hello, world!”:
let s = String::from("Hello, world!")
^
Here’s the problem: the cursor is now trapped after the text I typed, but still before the double-quote and the paren, but I need to add a semi-colon to close off the line. Here are my options:
right-arrow, right-arrow, ; (three key strokes, but I need to move my hand away from the main board, which takes extra time))
(In Vim) Esc (to exit INSERT mode), Shift+A (to bring the cursor to the end of the line and switch back to INSERT mode), ; (four key-strokes, but I stay on the keyboard)
Lift one hand from the keyboard, move the mouse to the end of the line and left-click to place the cursor after the paren, then ; (only one keystroke, but my hand needs to leave the keyboard completely)
Type out the auto-completed characters (most editors will overwrite the auto-completed text): Shift+'(to produce " on a UK layout keyboard), Shift+0 (to produce )) (four key-strokes)
Cmd+right-arrow, ; (three key-strokes, but I have to move my hand)
Perhaps the least bad is option 2, but it only works in Vim.
I could enable one of the co-pilots to auto-complete for me, but there are cases when I’d still want it turned off (for example when learning, or when I don’t want my thinking interrupted or distracted). There’s also no guarantee it will always autocomplete the ;, and highly likely to produce extra characters or even logic that I have to then erase.
I could use a different editor altogether, possibly with smarter features, or buy a decent keyboard with an End key closer to the main part of the keyboard.
There’s also Prettier, but it’s mainly for JavaScript/front-end. While there are plugins for other languages, you may not be keen on giving access to a (however well intended) Github repo with 20 stars and one contributor.
When all other options are exhausted, there is the obvious (or not so obvious) solution: disable auto-complete altogether.
Typing the closing quote and paren out still takes three key-strokes (since you can hold down the Shift key while hitting ' and 0), but there is no longer a cognitive penalty caused by re-orienting myself after the machine added characters that interrupted your typing flow.
There’s this notion you’ll probably hear if you spend enough time in software development (and probably many other industries):
The customers that contributes 20% of your revenue take 80% of your time
Many companies will agree. Essentially, the customers that have so little money to spend that they are looking for discounts and choose the cheapest tier available are also the ones with the most problems and the most needy of value from their suppliers. They will spend $10k per year and expect $1M in products and services, because that’s how great their needs are. They will call and email all hours of the day for issues big and small.
Meanwhile, for companies that have stable revenue and are growing, they tend to have well paid and capable engineering staff, and have figured out most of their problems already. They come to you to solve a specific problem they don’t want to look after themselves. More often than not, they won’t actually care that much if the price is $10k or $100k, as long as you solve the problem. They will mostly check in once a year to renew, but as long as the service is running they won’t even send you an email.
It’s not good or bad, just how things tend to play out.
So here’s my thought: when I find myself reaching out to my suppliers and partners, asking more and more specific questions about how they could lower the price and increase the service or improve the offering to suit my needs… I should probably take a step back. I am becoming that expensive customer.
And it often betrays something deeper: I am trying to offload too much of my business value to someone else, without wanting to pay for it. Instead of complaining that my provider is under delivering, I should rethink how I am structuring my business. Where is my value really coming from? What can I do to generate that value myself, without leaning on someone whose shoulders were not built for the weight I am applying?
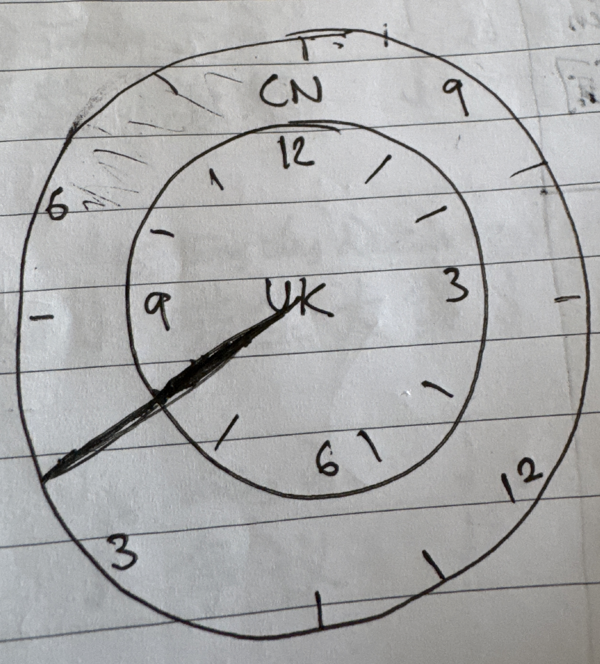
It started as a drawing in a notebook, as I was trying to visualise time in other time zones in relation to my own. It was a matter of practicality: I was struggling to coordinate a call between people located in the UK, China and Canada. It turned out there was no intuitive tool available. Lots of tables, time zone maps and a seemingly endless supply of Meeting Schedulers [tm] all to no avail: Every attempt to schedule was a back-and-forth of screenshots, drawings, and overshooting: either too late or too early somewhere. Some meetings just didn't happen as a result.
The thing is, we don’t need more tables or data, we need a way to relate. We need a way to, temporarily, speak each others' time.
I think one way to relate, especially for me, is through drawings and physical items. So my first attempt was drawing two clock faces overlaying each other, on a piece of paper, one shifted in rotation to represent the time difference.
I started with a traditional 12-hour clock face, but it somehow didn’t capture what happens when you cross into the next day. It was also fixed to one set time difference. So I drew another 24-hour clock face in my notebook. I then got a pair of scissors and cut it out. I pierced it with a straightened paper clip, jabbed it through the page underneath and secured the cut-out dial with a piece of tape over the paper clip. I could now rotate the cut-out over the paper underneath. I then drew another, wider, 24-hour clock face on the page underneath.
I had built the first version. It was already full of bugs (not even half of the hour markers aligned, for one), but it proved the concept. By rotating the 0-marker of the inner dial to the time difference, say 6 hours (as in the picture), I could then rotate the whole notebook and observe what my time (say, at 5 AM) would translate to in their time (11 AM).
In order to add a third time zone, I decided to go digital, and the result was Sanetime, an app for iOS and Android that helps you visualise time through the time zones. In other words, it lets you speak their time.
These days when I suggest times for meetings, it’s so much easier to just say “how is 7:30 AM your time?” because I can check it in a few seconds, without having to figure out what time zone this or that city is in. I open the app, type the first few letters, select the city and can see the time there and here.
I think that's why I prefer writing on a real piece of paper over anything digital. It somehow changes the way you think, the thought or idea changes as it is persisted on something physical.
You probably already know it's a myth that force closing apps (sliding it up all the way out of view so it disappears from recently used apps) on iPhone saves battery. In fact it drains the battery faster, because it interrupts the OS's algorithms for holding app data in memory for fast retrieval. Essentially, it costs more electricity to retrieve data from disk than it does to keep it in memory. By force closing it, you kick it out of memory, which forces the OS to load the whole thing from disk next time you open it.
Right, so given this, why hasn't Apple done something about it? Surely they will know by now that this is a widespread user behavior. They could add a prompt: do you really want to close this app and waste battery?
Well, they could, but that might come across as patronizing to some users. Maybe they made the call that the battery drain is only marginal and lets the user feel in control over their device. Yes, they might have to charge their phone a few minutes earlier, but that doesn't even compare with the impact of screen brightness or heavy background location fetching.
It's a great example of where technical reality doesn't align with user psychology.
companies “with poor revenue growth and unit economics” that are struggling to raise money
Silicon Valley Bank reports:
Venture capital firms focused on artificial intelligence are driving much of the growth in the startup market, while companies in other areas are struggling to raise cash.
Apple is the only company in the world that can, with significant certainty, tell a piece of software that the user is a) a human and b) a specific human.
Thanks to their fingerprint and face scanning technology ("a human is here") combined with iCloud login ("I know it is the same human as an hour ago") and an App Store that requires the user to provide credit card details ("and I know who it is").
If you try to run ( cd ios && pod install ) in your Expo project, you will now see:
==================== DEPRECATION NOTICE =====================
Calling `pod install` directly is deprecated in React Native
because we are moving away from Cocoapods toward alternative
solutions to build the project.
* If you are using Expo, please run:
`npx expo run:ios`
* If you are using the Community CLI, please run:
`yarn ios`
=============================================================
They still use pod install under the hood, only the command you run is changed for now. The plan is to use something else, and the most likely contender to replacepod install is Swift Package Manager.
Despite an unnecessarily complicated name, VoIP MS has sensible pricing and worldwide coverage for their voice-over-IP service, and could be a good alternative now that Skype has retired.
I use PageFind to make this blog searchable. It powers the search bar at the top of the page. It’s a neat tool, and while a bit clunky when it comes to UI customisation, it's very fast (both building and running) and supports modern search features like fuzzy find (when you type "call" it also lists results with "calls" and "calling") out of the box.
In 2025, a large number of websites still do not offer dark mode. It’s a good example of a feature that is repetitive and tedious to implement, and therefore perfect to achieve with the help of AI.
I am not saying rebuild your website in dark theme, just allow the option of switching to it. When you have your device set to dark mode (which 1/3 of users do - somewhat ironically, the site hosting the article does not support it), and the ambient lighting is low, it is inconvenient when a site - or app for that matter - blares #ffffff in your face.
We have developed a prompting technique that is both universal and transferable and can be used to generate practically any form of harmful content from all major frontier AI models.
They exploit the inherent problem with LLMs: data and code is the same thing:
Reformulating prompts to look like one of a few types of policy files, such as XML, INI, or JSON.
This was displayed after login, and can be enabled in the organisation settings. Essentially, if you share your customers' data with OpenAI, you get rewarded with tokens in return:
Turn on sharing with OpenAI for all prompts, completions, and traces from your organization to help us develop and improve our services, including for improving and training our models.
It’s a time-limited deal:
Get free usage of up to 250 thousand tokens per day across gpt-4.5-preview, gpt-4o and o1, and up to 2.5 million tokens per day across gpt-4o-mini, o1-mini and o3-mini on traffic shared with OpenAI through April 10, 2025.
Skype will be replaced by Teams in May 2025. All users will be migrated automatically. It’s kind of sad, but it makes perfect sense now that Microsoft has widespread usage of Teams by companies and individuals alike.
Imagine the scale of the migration project, getting all the contacts across, making sure no data is lost. That could have been a fun one to have worked on. Goodbye Skype, thank you for everything!
Created by n8n, the Sustainable Use License seems like a good option for new SaaS platforms:
Our goals when we created the Sustainable Use License were:
To be as permissive as possible.
Safeguarding our ability to build a business.
Being as clear as possible what use was permitted or not.
The license comes with three limitations:
You may use or modify the software only for your own internal business purposes or for non-commercial or personal use.
You may distribute the software or provide it to others only if you do so free of charge for non-commercial purposes.
You may not alter, remove, or obscure any licensing, copyright, or other notices of the licensor in the software. Any use of the licensor's trademarks is subject to applicable law.
The main points here are: use and modification only for internal business purposes (that’s the AWS clause, to prevent getting the Elastic treatment) and only being able to distribute/provide to others for non-commercial purposes.
The most popular app for Chinese learners, by far, is Pleco. It has a bunch of features, including flash cards, but the main attraction is the dictionary - up to date, with English translations even for the most obscure and newly popularised words.
However, the mode of usage has remained the same for years, if not decades:
Open the app
Search for a word
???
Profit
Today users sit in a classroom, iPhone in one hand and an iPad (or iPad pencil) in the other, typing or drawing in words into the search box at the top of the screen. The interface is built for easy navigation, with buttons that take you into words and characters, and back again. There are a fixed set of steps that you repeat each time you open the app. Those steps could be automated, and herein lies the first opportunity.
The other aspect is post-search: what happens once you've found the meaning? Users look up words, but there is no obvious next step for retaining the context. How do they come back to them?
The next must-have app in this space is still waiting to be built. The key is to understand what problems the users face today, and solve for that in a way that provides value.
In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment.
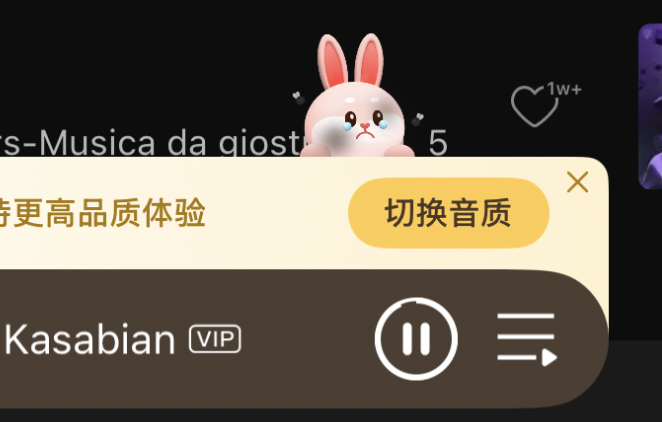
Here is QQ Music, a music app much like Spotify or Apple Music. You can create playlists and search for songs, comment on songs and playlists, and follow other users.
Here's what caught my attention. Inside the app is a mini game where you look after a digital pet. You have to wash it, feed it and play with it (one play mode is having it pick some music for you to listen to), to keep it happy.
If you forget the check in on it for a few days it starts getting dirty, hungry and sad. In order to look after it you need to buy food items and tickets to send it on music festivals. You can make friends with other users in the game, and they can actually spend their items on keeping your pet happy when you're away - and vice versa. You get some coins for free by interacting with the pet, but you can increase the amount of coins in your purse by watching ads.
So what is going on here? This digital bunny is helping the app and users connect emotionally. When the bunny is sad, the user is compelled to 1) interact with the app and 2) watch ads. The app uses all kinds of ways to remind the user of this connection - for example, if the pet starts getting really scruffy it pops up in the normal scenes in the app looking miserable.
What does this have to do with AI? Well, the above is just regular coding, excellent design and story telling. Now imagine using the power of an LLM to interact (talk and listen) and personalise (based on historical conversation) experiences like this.
The vast majority of blogs and articles focus on the training process, and how using data for training is this massive breach of privacy.
No one seems to even consider the usage side of LLMs.
A friend was trying out a Generative AI tool the other, started a conversation and casually dropped some personal information. After a few messages his colleague who was working on the same project shared his screen to show him the detailed list of all the things that had been said in the conversation.
"I forgot that someone else could read that"
This higlights the fact that hundreds of millions of people globally are inputting their innermost thoughts, fears and desires into LLMs every day. They upload X-rays, wedding photos and death certificates. They paste full WhatsApp conversation histories and type in secrets they would not dare tell another human. We can debate whether that is a good or bad thing, but it sure is a massive shift in how we interact with technology.
Expo is a framework and a platform for building native iOS and Android using React-Native. Expo.dev is a hosted platform for building, deploying and publishing iOS and Android apps.
This is my pipeline setup with GitHub Actions and Expo.
Ingredients
GitHub repo
Apple Developer account
Google Play Developer account
Expo account
EAS (the build service for Expo)
Expo and EAS
The Expo build service is called EAS. You get 30 free builds per month (as of today), which is more than enough for weekly releases.
EAS has two types of jobs for each platform: Build and Submit. The build step packages the app up into a format accepted by the respective provider, and the submit step actually uploads the build to the provider for beta testing.
You can view the builds and submissions in the web UI, but all the pipeline triggering happens in GitHub Actions. Expo has its own automation, but as usual there are always edge cases that need extra attention and are hard to cover in a managed service.
GitHub Actions
This is the main pipeline. It runs once a week on the main branch for both iOS and Android, and can be triggered manually anytime for either or both.
.github/workflows/release.yaml:
name: Release
on:
workflow_dispatch:
inputs:
platform:
type: choice
description: "Platform to release to"
options:
- ios
- android
- all
schedule:
- cron: "30 2 * * 3"
jobs:
release:
name: 📱 build and submit mobile
runs-on: ubuntu-latest
steps:
- name: 💻 Get Code
uses: actions/checkout@v3
with:
fetch-depth: 0 # Important for accessing the complete commit history
It updates the app.json file with the new build number. We have to do that since neither Apple nor Google will accept a new build with the same version and build number as a previous build. We still control the version number in code (in the app.json file), while the build number is managed by the CI/CD pipeline using this Python script.
def get_total_commits() -> int:
"""Returns the total number of commits in the current Git repository."""
return int(subprocess.check_output(["git", "rev-list", "--count", "HEAD"]).decode().strip())
def get_android_version_code(build_number: int) -> int:
"""Returns the Android version code"""
# Android requires version codes to be unique integers
# We add 10000 as a base to avoid conflicts with legacy builds
return 10000 + build_number
def update_app_json():
"""Updates the app.json file with the new build number."""
# Fetch total commits for build number
build_number = get_total_commits()
if build_number == 1:
print("Build number cannot be 1")
sys.exit(1)
# Read the existing app.json file
try:
with open('app.json', 'r') as file:
data = json.load(file)
except Exception as e:
print(f"Error reading app.json: {e}")
sys.exit(1)
if 'expo' not in data:
print("expo key not found in app.json.")
sys.exit(1)
if 'android' not in data['expo']:
print("android key not found in app.json.")
sys.exit(1)
if 'versionCode' not in data['expo']['android']:
print("versionCode key not found in app.json.")
sys.exit(1)
if 'ios' not in data['expo']:
print("ios key not found in app.json.")
sys.exit(1)
if 'buildNumber' not in data['expo']['ios']:
print("buildNumber key not found in app.json.")
sys.exit(1)
if 'version' not in data['expo']:
print("version key not found in app.json.")
sys.exit(1)
# Update the app.json data
data['expo']['android']['versionCode'] = str(android_version_code)
data['expo']['ios']['buildNumber'] = str(build_number)
# Write the updated data back to app.json
try:
with open('app.json', 'w') as file:
json.dump(data, file, indent=2)
print("app.json has been updated successfully.")
except Exception as e:
print(f"Error writing app.json: {e}")
sys.exit(1)
if name == "main":
update_app_json()
But what happens if the build for iOS was run manually on Tuesday, when the automated build runs on Wednesday?
Excellent question! The problem here is again that the providers will reject builds with the same build version as a previous build. This means manual runs could interfere with the automated runs, and the submission step would fail as Apple/Google rejects it due to build number collision.
This is where the eas-build.py script comes in. It checks if there's already a build for the current version and handles the conflict gracefully.
If there is already a build in EAS with the same build number, we do not submit anything to the provider (Apple or Google).
Does that mean you skip the build entirely?
No. We could do that, but that might cause other problems down the line. Imagine that there are no commits for a few weeks, or even months. Then suddenly there's a critical bug that needs fixing, we jump on it, get a fix together and submit a new build. But since the last successful build was weeks or months ago, some new dependency or other change outside of our control could mean the pipeline fails. There could be multiple failures that have accumulated over time, and they now block the release. Now we have to sit down and try to understand the pipeline again, and stay up all night trying to fix it, before we can ship the bug fix!
So instead of skipping the build, we meet in the middle: run the build step, but don't submit it. This keeps the pipeline warm and alerts if the build breaks for some other reason than our code change, without firing off needless submissions that fail.
def get_last_successful_build_date(platform: str) -> str:
"""Returns the date of the last successful build from EAS."""
try:
# Get the last successful build info from EAS
result = subprocess.check_output(
["eas", "build:list", "--non-interactive", "--json", "--limit", "1", "--platform", platform]
).decode().strip()
builds = json.loads(result)
if builds and len(builds) > 0:
status = builds[0].get("status")
if status == "IN_PROGRESS":
raise RuntimeError(f"Last {platform} build is still in progress")
if status == "IN_QUEUE":
raise RuntimeError(f"Last {platform} build is still in queue")
if status == "PENDING_CANCEL":
raise RuntimeError(f"Last {platform} build is pending cancel")
if status == "NEW":
raise RuntimeError(f"Last {platform} build is new")
# The completedAt field contains the build completion timestamp
return builds[0].get("completedAt")
return None
except (subprocess.CalledProcessError, json.JSONDecodeError, KeyError) as e:
print(f"Error getting last {platform} build date: {e}")
return None
def has_new_commits_since_last_successful_build(platform: str) -> bool:
"""Returns True if there are new commits since the last successful build."""
last_build_date = get_last_successful_build_date(platform)
if not last_build_date:
# If we can't determine last build date, assume there are changes
print(f"Could not determine last {platform} build date, assuming changes needed")
return True
result = subprocess.check_output(
["git", "log", f"--since='{last_build_date}'", "--oneline"],
).decode().strip()
has_changes = bool(result)
if not has_changes:
print(f"No new commits since last successful {platform} build ({last_build_date})")
return has_changes
def build_platform(platform: str) -> None:
"""Execute the appropriate build command based on whether there are changes."""
base_command = ["eas", "build", "--non-interactive", "--no-wait", "--platform", platform]
if has_new_commits_since_last_successful_build(platform):
# Build and submit to store
command = base_command + ["--auto-submit"]
print(f"Building and submitting {platform} app to store...")
else:
# Build only (keep pipeline warm)
command = base_command
print(f"Building {platform} app without submitting (just to keep pipeline warm)...")
try:
subprocess.run(command, check=True)
print(f"Successfully initiated {platform} build")
except subprocess.CalledProcessError as e:
print(f"Error during {platform} build: {e}")
sys.exit(1)
if name == "main":
if len(sys.argv) != 2 or sys.argv[1] not in ["ios", "android"]:
print("Usage: python eas-build.py <ios|android>")
sys.exit(1)
platform = sys.argv[1]
build_platform(platform)
About scheduled builds
We could just trigger this manually, but there is something rather useful about builds that run on a schedule, for a number of reasons:
Our perception of time is warped to say the least, and having a trusty machine tick away every week is a good way to make sure you remember to ship.
The schedule establishes a habit for you, in that you know every Wednesday at 02:30 AM the pipeline will run and build the app. If you have some bug fixes or new features to get out, your mind will naturally start planning based on the schedule. You have given yourself a weekly, artificial deadline.
And as mentioned before, it means that the pipeline will run even if nobody has pushed any new commits to the repo, catching build errors we might otherwise miss.
Apple review times
Apple reviews are notoriously arbitrary, in many regards but in particular in the time it takes to review a new build. One way to help avoid getting stuck behind the review is after you get a new version approved (say 1.0.0) to immediately bump the version (to 1.0.1) and run the iOS pipeline to submit it to TestFlight. That way you get over the first hurdle of the initial review for beta testing, which can sometimes take longer than the actual publishing review (the last step before hitting the App Store). After the first beta review, subsequent builds do not require approval until you decide to publish.
Conclusion
This automated pipeline setup provides several benefits:
Weekly automated builds ensure the pipeline stays healthy
Manual triggers allow for urgent releases when needed
Smart handling of build numbers prevents submission conflicts
Keeping the pipeline "warm" helps catch issues early
The combination of GitHub Actions and Expo makes for a reliable and maintainable mobile app deployment process that works well for both scheduled and on-demand releases.
Contact me
Anything missing from this post? What problems do you have with your mobile app deployment pipeline? What do you think is the most annoying part of the process? I'd love to hear from you!
How do you write a Kubernetes Operator from scratch? To answer this question as simply as possible I wanted to find the bare minimum needed to write the blueprint for a custom resource, generate the client code and write a reconciler.
But I wanted it to do something external to the Kubernetes cluster, not just mock about with Pods or Deployments, because in my mind that is the real power of custom controllers: they can do just about anything. There are Kubernetes controllers to create cloud resources (EC2 instances, S3 buckets, you name it), managing stateful applications and even ordering pizza.
So here is the Tweet Operator: a Kubernetes custom controller that manages the lifecycle of the custom resource Tweet: each resource has a text field, and when created, the operator posts the tweet. It then monitors the details of the tweet and posts back retweet and like counts to the status field of the Kubernetes custom resource.
The first hurdle was to actually get access to the Twitter API: they have recently changed it, so in order to post things to Twitter you need to first enable what they call Extended access. This is far from obvious, and by the looks of it will probably change again in the future.
I followed a short YouTube video to set up a basic Twitter bot using a couple of existing Twitter Go libraries. The code is here.